市中にどのくらいコロナが蔓延しているか外出するたびに気になっていたのだが、いま住んでいる地域の情報をリアルタイムで伝えてくれるメディアがなかったので、自分で作った。すでに半年以上稼働しており安定してきたので、あとで思い出せるようにどうやってやったのかをまとめる。
やったこと
次のポストを行うTwitter Botの作成。
- 毎日の新型コロナウイルス感染者数のポスト(自治体の公式発表にもとづく)
- コロナ危険エリアを知らせてくれる色塗りマップの作成
- コロナ感染者数のランキング
- ワクチン接種数・接種率
- 実効再生産数(Rt)のグラフ
[更新]昨日の愛知県内の実効再生産数(Rt)は、名古屋市は1.55、豊田市は0.94、豊橋市は1.02、一宮市は0.8、岡崎市は2.06、愛知県全体は1.2でした。グラフは実効再生産数の推移を表しています(2021-07-23現在)。 pic.twitter.com/YjVXq5H2Jp
— aichi_covid19 (@AichiCovid19) July 23, 2021
[速報]名古屋市の本日の新型コロナウイルスの新規感染者数は79人(先週の木曜日に比べて+51人)でした。詳細は公式サイトを参照 > https://t.co/skZIlcaR7J
— aichi_covid19 (@AichiCovid19) July 22, 2021
愛知県新型コロナ危険エリアランキング(昨日まで直近1週間の10万人あたり新型コロナウイルス感染者数)
— aichi_covid19 (@AichiCovid19) July 23, 2021
1位 23人: 幸田町
2位 21人: 飛島村
3位 19人: 碧南市
4位 17人: 常滑市
5位 15人: 東海市
6位 14人: 西尾市
7位 12人: 名古屋市, 長久手市
8位 10人: 豊橋市, 瀬戸市, 蒲郡市(以下略) pic.twitter.com/FOpxoQSAFg
昨日まで直近1週間の新型コロナウイルス感染者数ランキング
— aichi_covid19 (@AichiCovid19) July 23, 2021
1位 288人: 名古屋市
2位 39人: 豊橋市
3位 25人: 西尾市
4位 24人: 岡崎市
5位 19人: 春日井市
6位 17人: 東海市
7位 14人: 瀬戸市, 碧南市
8位 13人: 豊川市, 一宮市
9位 12人: 小牧市
10位 11人: 豊田市
11位 10人: 常滑市(以下略)
[更新]現在の愛知県の新型コロナワクチンの総接種回数は4156224回(1回目接種2466811回、2回目接種1689413回)です。1回目接種率は32.77%、2回目接種率は22.44%です。詳しくは首相官邸サイトを参照 > https://t.co/WrxRRYET47
— aichi_covid19 (@AichiCovid19) July 22, 2021
サービス構成
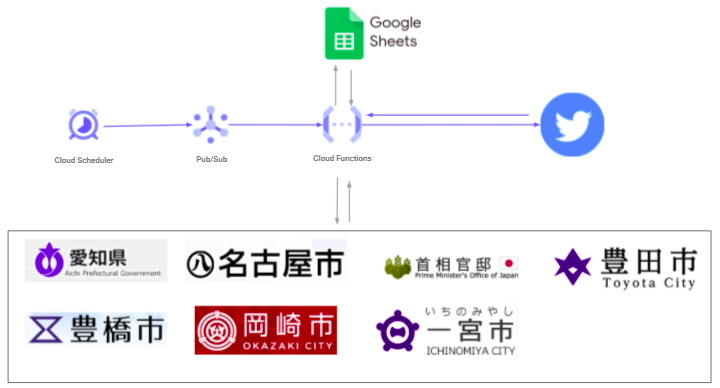
- Cloud Schedulerを使ってイベントをCloud Functionsに送る
- Cloud Functionsは各自治(愛知県、名古屋市、豊田市、豊橋市、岡崎市、一宮市)および首相官邸のWebsiteをクロールし、その日の感染者数、前日の感染者数、人口、ワクチン接種数などを取得する。スクレイピングまたは、csvやxlsx、pdfなどのデータをダウンロードしてデータ化している。
- スクレイピングまたはファイルから得たデータをGoogle Spreadsheetsに書き込んで保存する。過去のデータを使う場合は、このGoogle Spreadsheetsから読み込んで使う。
- 加工したデータをTwitterにポストする。また、過去のポストしたデータをAPIで取得する。
技術的な詳細と開発の経緯
はじめはスクレイピングおよびデータ取得、Twitterへのポストをローカルでcronで動かすことにしていた。この時点でやっつけた課題は次のとおり。
- PDFを含む複数の異なるWebサイトからのデータ取得。愛知県の対コロナ体制は非常に複雑であり、名古屋市・豊橋市・豊田市・岡崎市(途中から一宮市が追加)は独自にコロナ感染者や死亡者などを発表しており、愛知県はこれら以外の自治体分に関して発表している。
- つまり、ひとつを見れば全部わかるサイトというのがなく、これら6つのすべてのWebサイトを見ないと、コロナ感染者数の全体像が見えないひどい仕様である。それぞれのウェブサイトは全く互換性がなく、PDFで発表したりベタ打ちhtmlだったりテーブルだったりするお役所行政。また、PDFは紙に印刷する用に作られており、データ提供のフォーマットとしては最悪。
- PDFはCamelot-pyで、普通のhtmlはBeautifulSoupで、xmlはfeedparserで読み取っている。PDFがやはり一番曲者で、よくデータ位置がずれるし、そもそも数百ページのPDFを読み取るのにすごい時間とコンピューティングリソースがかかる。
- htmlも曲者で、市の担当者がその日の気分で文章を変えたり文章の位置を変えたりするので、色んなパターンが来ても対応できるようにしないといけない。安定してデータを取ってこれるようになるまで時間が必要である(どんなパターンが来るのか学習する必要があるため)。
- 色塗りマップの作成
- 愛知県の地図上をコロナ患者の発生者数で色塗りをした。どこで感染が起こっているのかを視覚的にわかるようにするため。
- これにはgeopandasを用いた。geopandasは地図上を色塗りできるライブラリで、インストールがやや面倒である。Linuxを使うかAnacondaを使えばインストールは簡単でよいが、Windowsでpipを使う場合はC++のコンパイラなどをいれる必要がある。
- geopandasで使う地図データは、国土交通省国土数値情報行政区域データを用いた。人口は愛知県のウェブサイトから入手できる。
- 実効再生産数(Rt)のグラフの作成
- ワクチン接種数と人口に対する割合
- 政府CIOポータルのウェブサイトで掲載されているのだが、なぜか医療従事者向けはダッシュボードとは別に首相官邸サイトに記載されているため、全体数をリアルタイムに知るためには双方からデータを取得する必要がある。
- 首相官邸サイトがたまにエクセルのファイル名を変えるのが曲者。
これらは、はじめはローカルのラップトップ(Ubuntu)で動かしていた。これがくせ者で、こどもがパソコンで遊んだあとに電源を消してしまったり、重い処理をして固まったままになってたりしてうまく動いていないことがあった。また、つけっぱなしなので電気代もそれなりにかかる。
- この問題を解決するために、Cloud Functionsを使うことにした。
- いま考えればHerokuとかのほうがよかったのかもしれない。
- Cloud Functionsは完全に素人なので全然使い方がわからず、ちゃんと動くものがデプロイできるまでやや苦労した。
- requirements.txtの書き方やコード自体のデプロイは比較的シンプル。
- 料金体系が結構複雑。Cloud Schedulerの料金、デプロイ時のCloud Storage料金、Cloud Functionsの料金など全部でいくらかかるのかパッと見よくわからない。
- /tmp/にファイルを保存できるというのがはじめ気づかなかった。
- メモリ設定など。PDFを読み込む動作はかなりメモリを使うため、メモリをけちった設定になっているとメモリ不足で落ちる。どのくらいメモリが必要かの見積もりが重要。
コード
githubにある。が、もはや使っていないファイルも多く、参考になるかは不明。


コメント