
去年と今年は車による出張が多く、かつ毎日クルマで通勤していることもあって車内で過ごす時間が長い。前はラジオを聞いていたり英語を勉強したりしていたが、最近はずっと本を聞いている。本を聞いているというのは若干変な表現だが、つまりは電子書籍を読み上げで聞いている。これはすごいおすすめで、読みたかった本がどんどん読めるし、何時間運転していても苦にならない。これはいい!と思ってKindleでどんどん本を買っていたら、費用がけっこう嵩んできた。一方で、家の本棚を見ると大量に読んでない本が積んである現実がある。読んでいない(紙の)本がたくさんあるのに、本(電子書籍)を新しく買うのはどうなんだろう、と当然考え、自分で電子書籍にすることにした。いわゆる自炊である。
手順は下記の通り。
- 裁断する本を選ぶ
- 本を手で引っ張って分解する
- 分解した本の背表紙側を裁断機で裁断する
- スキャンする設定をパソコン側で整える
- スキャンする
- スキャン済ファイルに名前をつけて保存する
- デバイスで読む
裁断する本の選択
この工程が一番むずかしい。決断が早い人にとっては何でもない工程だと思うけれど、一度本を裁断すると二度ともとの形には戻らないので、決意が必要である。電子書籍にするにあたって躊躇するのは、思い入れのある本だったり、自分で高いお金を払って買った本だったり。逆に躊躇がないのは、古本で安く買ったものとか、そのまま置いておいてもまず読まないであろう本とか。とりあえず、古本で買った本で電子書籍として読んでみたいものから裁断することにした。
分解
この工程は単に力技である。本を数十ページ単位で引きちぎる。この引きちぎる工程は、古い本であればあるほど背表紙がもろくなっており、やりやすい。文庫本であれば、裁断機で40枚程度裁断できるので、40ページずつ引きちぎる。立派なハードカバーの本であれば、裁断するのが20枚が限界なときもある。
ちなみに、この分解の過程ではそれぞれの出版社やシリーズの製本の具合をいやでも確認することになるため、本に対して思い入れが出てくる。講談社文庫は背表紙が強いな、、とか京極夏彦は分厚くて手強いなとか。
裁断
CARLの裁断機(カール事務器 裁断機)で裁断する。裁断後の紙のサイズに極端なずれが生じないように、だいたい同じ位置で裁断するのを注意する。また、本を引きちぎる際に強い力を加えると、本が斜めになったままになることがある。こうなっているとそれぞれの紙のサイズが変わってきてしまうので、裁断する前に引っ張って伸ばして固定する。下記が斜めになっている例。

スキャンする設定
Scansnap (ScanSnap iX500)の設定を整える。基本的に本の本文は白黒で、本の表紙や裏表紙はカラーでスキャンしている。あとで忘れないために、設定のスクリーンショットを下記に載せておく。Image QualityはこのBestがよい。300dpiないと活字の判別に際して読みにくいときがある。絵がない文庫本などは白黒のほうがファイルサイズを節約できてよい。スキャンする際に気をつけておけば、自動回転はオフにしたほうがうまくいった。
スキャンする裁断した本は一気にScansnapにセットできないので、スキャンが進んできたら補充する。補充し忘れてスキャンが終わってしまわないように、Continue Scanning After Last Pageにチェックをしておくのが重要。また、できあがった電子書籍を読み上げたい場合、日本語OCRをONにしておくと文字情報がPDFに残る。ただし、いまいちな点もあるので、結局これでは完璧にならない(後述する)。

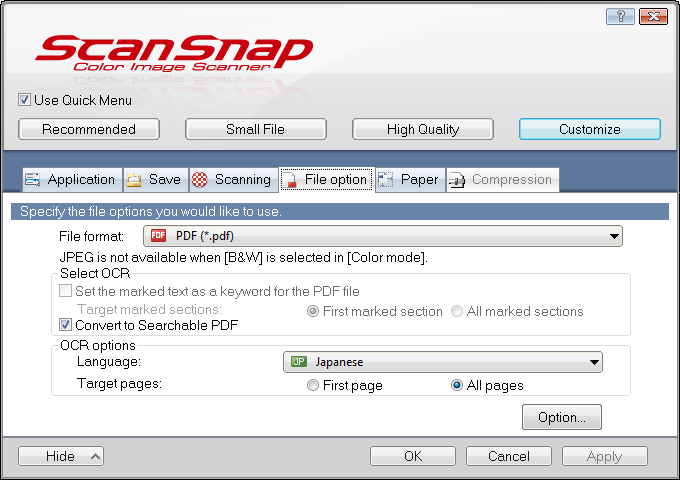
スキャン
ボタンを押してスキャンを開始する。一気に本を置いて置けるとよいのだが、実際にはスキャナの紙置き場はそれほどたくさん紙を置けないため、何回かにわけてスキャンする紙(裁断した本)を補充する必要がある。途中で2枚同時に吸い込んだり紙が詰まったりすることがまれにあるので、それらは手で直す。
下記がスキャンしたあとの本をとりあえず輪ゴムで束ねたもの。このような束ねた本が大量に残ることになる。これらは使いみちがないのだけれど、どうしたらいいだろうか。

名前付け
保存するファイル名をスキャン後に見て決める。名前を適切につけないとあとでどれがどれだかわからなくなるので、命名ルールをきちんと自分の中で決めておく。
読む
単に読むだけであれば、世の中にはたくさんいろんなアプリケーションがある。単なるPDFファイルなので、何でも読める。普通の電子書籍はKindleで買っているけれど、このスキャンした電子書籍はKindleだと読み上げてくれないので、Apple Booksを使っている(下記が例)。Androidでもいい感じに読み上げてくれるアプリがあるといいのだけれど。
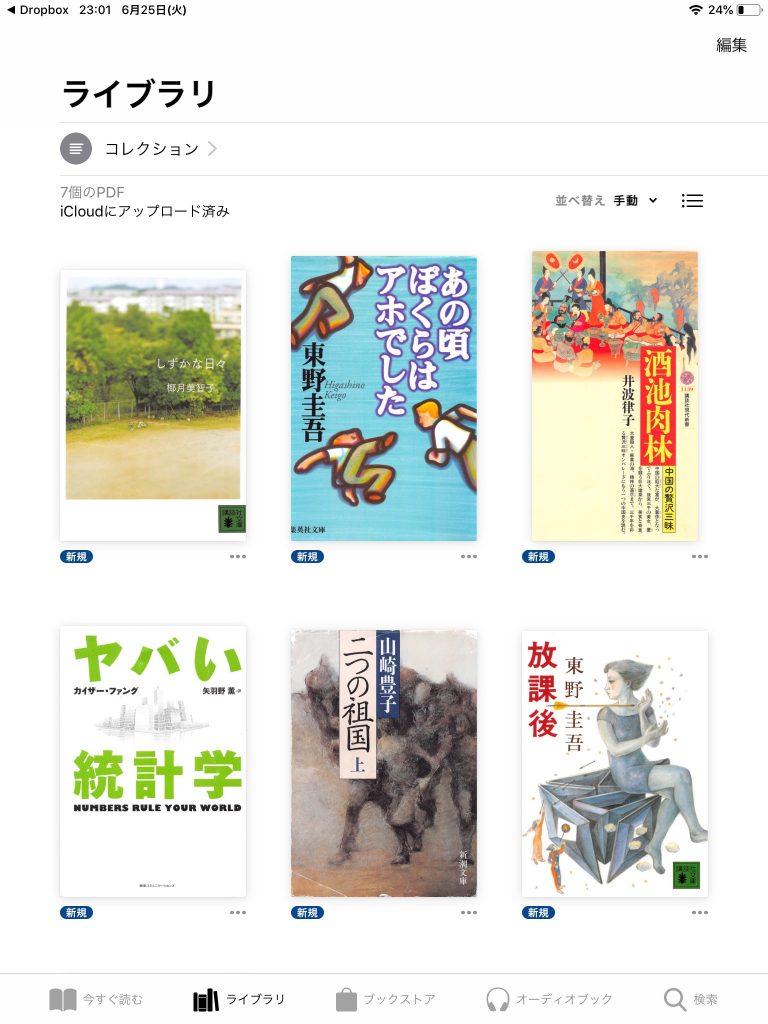
読み上げに際していま抱えている問題は、OCRで読み取った文字がすべて読み上げられてしまうということである。それはつまり、ページ番号やページ番号の横にある章番号などもすべて読まれてしまうのだ(下記の例のように、大抵の本にはページ番号や章タイトルなどが余白に書き込まれている)。これはかなりいまいちで、1ページごとにページ番号を聞く羽目になる。これを回避するには、本文部分のみトリムし、改めてOCRにかける必要があるだろう。

追記:
音声で読み上げを聞くのにあたって、今の所のベストプラクティスは下記のとおり。
- Nuance PDFを使って、各ページにあるページ番号や章タイトルなどの本文以外のところを切り取る(トリムする)。ページ番号や章タイトルは読み上げにあたってはかなり邪魔なので消したほうがよい。保存版をとりあえず別途バックアップしておく。トリムすることで本文ではないところ(目次など)は中途半端なところでちぎれてしまうからである。
- 同様に、Nuance PDFを使ってOCR(文字認識)をかける。Nuance PDFのほうがScansnapのデフォルトOCRであるABBYYより縦書き日本語認識能力が高いように感じる。
- 読み上げはApple Books一択である。Androidでは自炊したPDFを満足に読み上げてくれるソフトをまだ見つけられていない。どうやったらできるのだろうか。
Nuance PDFを使っている理由はScansnapにくっついて来たからである。PDFを編集するソフトウェアとしてはAdobe Acrobatが有名だが、NuanceはAdobeより安く、かつAdobe優れているところもあって大好きなソフトだ。この縦書きOCRもその一つ。Scansnapを買ってよかったと思うことのひとつだ。


コメント
[…] 本をスキャンして電子書籍にするとき用メモ […]